近日,谷歌工程师Rachel Potvin和Josh Levenberg在《美国计算机学会通讯》上发表了一篇论文,介绍谷歌为什么采用一个定制的大型单体共享库。该库有一个集中式源代码控制系统管理。谷歌采用该方法已达16年之久。如今,谷歌大部分的资产都存储在这个单体共享库中。
谷歌的软件开发人员不断增加,其代码库也成倍地增大,管理代码库的技术也在相应地发展。为管理这个谷歌95%的软件开发人员都在使用的代码库,谷歌开发了自己的版本控制系统。该集中式系统是谷歌开发工作流的基础,支撑着谷歌“基于主干的开发策略”,确保了代码库的健康,包括静态分析、代码清理和简洁的代码评审。这个代码库包含大约10亿个文件,86TB的数据,其中包含大约20亿行代码,18年间大约产生了3500万次提交。通常,一个工作日就会有16000次提交,以及24000个来自自动化系统的提交。此外,该库每天还要处理数以10亿计的文件读取请求以及每秒500000次查询。
管理这样一个大规模的库及其相关活动是一项巨大的挑战。虽然经过了多年的试验,但谷歌还是没能找到一个商业或者开源版本控制系统来管理这种规模的单体代码库。于是,谷歌基于标准的基础设施(最初是BigTable,现在是Spanner)构建了Piper来存储和管理它。Piper分布在谷歌全球范围内的10多个数据中心里,基于Paxos算法来保证副本之间的一致性。该架构提供了很高的冗余水平,并帮助谷歌的开发人员优化网络延迟,而不管他们工作地点在哪里。该系统的工作流程如下:
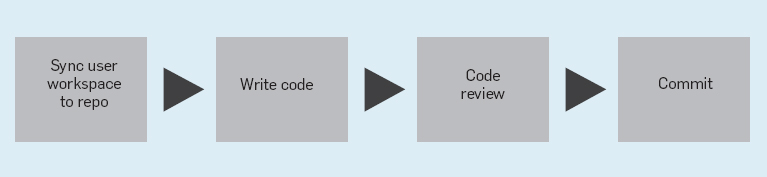
大多数开发人员都是使用Clients in the Cloud(CitC)访问Piper。该系统包含一个基于云的存储后端和一个Linux特有的文件系统FUSE。CitC 支持代码浏览和常见的Unix工具。开发人员可以浏览和编辑Piper库中的文件,但只有修改过的代码会存储在用户的工作区里。也就是说,CitC工作区通常只占用很小的存储空间。
谷歌在这个巨大的Piper源代码库上践行着“基于主干的开发”策略。大多数Piper用户都工作在“主干”的唯一最新副本上。代码库的修改顺序是一个串行序列。提交完成后,其他所有的开发人员立即就可以看到和使用新的代码。Piper的所有用户都使用一个一致的代码库视图,这可以避免代码合并的痛苦,是单体大型代码库能够具备如下优势的关键所在:
- 统一版本控制
- 广泛地代码共享和重用
- 简化依赖管理,避免菱形依赖
- 原子修改
- 大规模重构
- 跨团队协作
- 灵活的团队边界和代码所有权
- 代码可见性以及清晰的树形结构提供了隐含的团队命名空间
总之,将所有源代码存储在一个公用的版本控制库中,让代码库维护人员能够有效地分析和修改源代码。类似Refaster和ClangMR这样的工具可以利用谷歌代码库的单体视图执行高级的代码转换。单体代码库包含了所有依赖信息。旧的API可以很有把握地删除,因为可以证明,所有的调用者都已经迁移到了新API。
虽然有许多好处,但构建这样一个庞大的单体代码库也有几个方面的问题需要权衡。
工具投入
单体代码库在许多方面简化了工具,但它们需要能够扩展并适用于代码库的规模。例如,谷歌开发了一个Eclipse IDE插件,以便能够在该IDE中操作这个巨大的代码库。谷歌的代码索引系统为静态分析、代码浏览工具交叉引用等提供了支持。这些工具都需要不断的投入以适应代码库的不断增长。除了构建和维护这些可扩展的工具之外,谷歌还需要承担运行这些系统的成本,有些是计算密集型的。
代码库复杂性
虽然单体模型让代码结构更容易理解,但却让代码发现变得更困难。随着代码库规模的增长,像grep这样的标准工具就无法使用了。开发人员需要能够查看代码库,找到相关程序库,并看看如何使用它们以及谁编写了它们。这就需要有代码搜索和代码浏览工具。此外,由于添加依赖变得简单,所以开发团队对依赖图的考虑就比较少,这增加了代码清理时犯错的可能性。因此,需要有依赖重构和代码清理辅助工具。
代码健康
谷歌在代码健康上投入了大量的精力。例如,专用工具可以自动检测和删除无用代码、分派代码评审任务等。
另外,随着分布式版本控制系统(如Git)的流行,谷歌也考虑过是否用Git取代Piper作为基本的版本控制系统。由于外部合作伙伴和开源协作方面的原因,谷歌的Android和Chrome团队就使用Git。Git社区强烈建议使用更多更小的代码库,而且Git克隆操作会把所有内容都复制到本地机器上。因此,如果要迁移到Git,谷歌就需要把那个巨大的代码库分割成成千上万的小代码库。对谷歌的开发人员而言,这意味着文化和工作流程的变革。鉴于单体代码库所带来的好处,他们放弃了这种迁移。
这篇论文在Hacker News上引发了激烈的讨论。网友rzimmerman认为,如果没有人致力于维护构建环境、自动化测试和开发环境,那么大型单体代码库的许多好处将不复存在。如果运行测试、生成构建需要几个小时才能完成,就会严重降低团队的效率。但wtbob认为,多代码库只是模糊了单体库中明确需要完成的工作,但并没有减少相关工作。例如,在单体库中,一项破坏性修改所产生的全部影响立即就会显现出来;但在多代码库的情况下,有一些影响要在很长时间之后才能发现。
网友hpaavola认为单代码库确实便于处理依赖问题。据他介绍,他们的产品族包含多个产品。每个产品都有自己的代码库,每个代码库又有自己的功能测试。每当测试自动化核心功能发生变化,他就需要为每个产品的代码库生成一个分支,并逐个进行测试,看修改是否破坏了向后兼容性。如果破坏了,他就需要通过向多个团队提交pull request修复测试。这是一个痛苦的过程。在单代码库的情况下,修改要容易得多,只需要生成一个分支,提交一个pull request。
原创文章,作者:老D,如若转载,请注明出处:https://laod.cn/2256.html








评论列表(1条)
有意思