百度在搜索上跟google还是有很大差距的,尤其是google支持很多搜索语法,非常强大。所以这里这里写了个简单的获取google搜索结果的脚本。但是google做了防爬取限制,使用一般的正则匹配是不行的,这里用的是google的ajax的接口,但是使用起来还是有些问题,没有完全解决。
获取google搜索结果的Python代码#! /usr/bin/env python #coding=utf-8 import urllib2,urllib import msvcrt import simplejson import sys
def CatchURL(key,num):#抓取链接 url = ('https://ajax.googleapis.com/ajax/services/search/web?v=1.0&q=%s&rsz=8&start=%s') % (key,num) try: request = urllib2.Request(url) response = urllib2.urlopen(request) results = simplejson.load(response) URLinfo = results['responseData']['results'] except Exception,e: print e else: for info in URLinfo: result.append(info['url'])
def RemoveRepeat(List):#列表去重 New_List = [] for i in List: if i not in New_List: New_List.append(i) return New_List
def save(List): f = open("result","w") for i in List: f.write(i+"\n") f.close()
if __name__ == '__main__': searchstr = raw_input() pagenum = input() result = [] for i in range(1,pagenum+1): CatchURL(searchstr,i) result = RemoveRepeat(result) save(result) print "DONE!"
运行程序,第一行输入搜索的内容,第二行输入搜索的页数,然后会在程序同目录下生成result文件,里面是获取并且去重后的url,但是程序运行的时候可能会出现如下的情况.
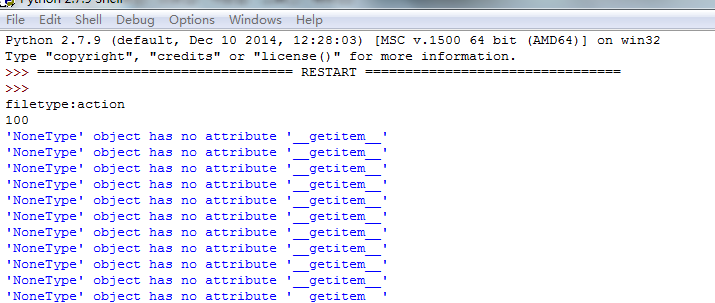
那是因为google检测到非正常的请求,导致无法获取搜索结果,暂时未能解决。
原创文章,作者:老D,如若转载,请注明出处:https://laod.cn/2046.html





评论列表(96条)
之前一直都想过尝试抓取Google搜索结果了,
API我总觉得很容易被封(个人认为而已),
我在想用Selenium一类的浏览器自动化软件来访问Google搜索结果,
再分析出HTML的内容。
这个应该是比较笨,但比较稳定的方法。
(个人认为HTML不会常常改,即使改了也可用比较智能的视觉条件来分析)
不知现在老D有没有其他方法,如果没有的话,我就做出来试试看。
@宅男的野心:不知道你尝试的selenium可以吗?好像如果不换ip的话,就直接selenium的话我这边试了只能爬到7页数据,很快就封了。
之前一直都想过尝试抓取Google搜索结果了,
API我总觉得很容易被封(个人认为而已),
我在想用Selenium一类的浏览器自动化软件来访问Google搜索结果,
再分析出HTML的内容。
测试
获取Google搜索结果的Py脚本 ←读成"获取Google搜索结果的屁眼脚本"…
老刀,给你友情测试了一下,你的输入框需要验证啊.
@1:尼玛,刷了我一百多条,我用的是第三方评论插件
@老D:100条都是我手下留情了,关得快.
@1:哈哈好玩
@wiki:写个循环就好。
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs
测试老刀的bbs